Monitoring and Analysis of Public Procurement
Data analysis allows to forecast the participants and prices for new tenders and auctions. Analytics is used for studying of customers and suppliers activities. Users see the statistics of wins and participations, in which public procurement category the supplier participated and who his major customers are.
The System reached Byndyusoft after the initial attempted development by a team of one of the largest outsourcers. The way it was handed over, it was not fulfilling the purposes in view.
Information on public procurement occasionally disappeared, information was coming with big delay, and auctions and tenders search was working incorrectly.
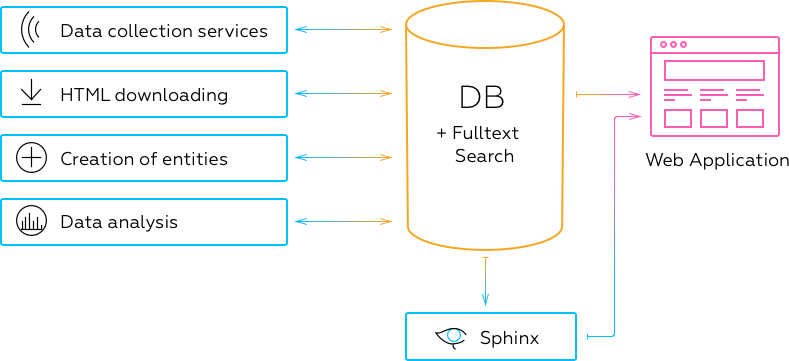
- The core of the whole system was MSSQL database (Shared DB integration style)
-
Full-text search public procurement auctions and tenders was based on Sphinx, other search was developed with the use of Fulltext Search MSSQL - Subsystems for downloading and processing of data were using DBMS for saving of status and exchange of with each other
- Data denormalization was implemented with the use of triggers, calculated column and View, which were recalculated according to schedule.
Overall, the right set of technologies was employed, however the architecture turned out to be
It was impossible to sell the system like this. The client suffered losses and investor confidence. It was necessary to turn the tide and release a stable version for sale to users.
Byndyusoft decided to stabilize the income of public procurement data, gradually rewrite the current code, and cover the code with tests.
Transition to horizontal scalability
Architecture of the decision was changed in two stages and moved to microservice architecture. At first, as an alternative to integration in Shared DB style message queues were used.
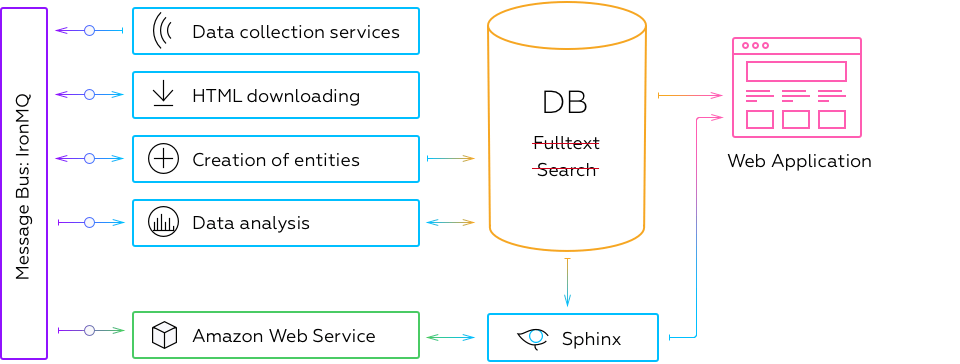
Data on documents were removed from the DB to the cloud storage AWS S3. This significantly reduced the load upon the DB, flow of information on documents started to come directly from the cloud.
Sphinx was reconfigured according to best practices relating to this engine to get maximum
performance out of it.
Data flows in subsystems of data collection and analysis started to come through the queue, which significantly reduced the load on the database server. IronMQ cloud queue was employed, which is a part of AWS infrastructure.
All of this allowed to horizontally scale the load on all subsystems at the cost of acquisition
of the most cheap
Current load
Project services continuously collect the following data from the official site of public procurement:
- Data on new public procurement tenders and auctions
- Changes in current tenders and auctions
- Changes in details of suppliers and customers
- Data on signed agreements
About 100 thousand of different changes are processed every day. All data are analyzed with a delay not more than 10 minutes. Data processing includes:
- Analysis of document text and name of tender/auction
- Clusterization and tagging of texts, location of statement of work in the documents
- Searching for similar tenders/auctions of the customer, updating of data for similar tenders/auctions in the DB for the purpose of displaying to user
- Recalculation of analysis relating to predictions of participants and prices
- Sending of notifications to users
Changes after release
After the system was released there arose a demand for reduction of load on the DB, because its volume grew up to 500 GB and optimization of queries started giving problems.
Moreover,

It was decided to move part of manuals, lists and other information, which did not affect the analytics, to NoSQL storage.
Sphinx was cloned to several servers, which allowed to find data in less than 0,5 seconds.

Within 8 months, a team of 7 persons rewrote existing subsystems and implemented key features of Zakupki360 project. Currently, the project has switched to paid subscription and is successfully selling data to users.
After adoption of